> For the complete documentation index, see [llms.txt](https://vladislaveremeev.gitbook.io/qa_bible/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://vladislaveremeev.gitbook.io/qa_bible/test-dizain/dynamic-black-box.md).
# Dynamic - Black box
*Разработка тестов методом черного ящика (black box test design technique): Процедура создания и/или выбора тестовых сценариев, основанная на анализе функциональной или нефункциональной спецификации компонента или системы без знания внутренней структуры. (ISTQB)*
*Основанные на спецификации методы проектирования тестирования используются для получения контрольных примеров из базиса тестирования, определяющего ожидаемое поведение элемента тестирования. При использовании этих методов входные данные для тестирования контрольного примера и ожидаемый результат получаются из базиса тестирования. Выбор, какие из основанных на спецификации методов проектирования тестирования использовать в каждой конкретной ситуации, зависит от природы базиса тестирования и/или элемента тестирования, и от присущих рисков. (ГОСТ 56920)*
Все specification-based или Black Box testing techniques могут быть удобно описаны и систематизированы с помощью следующей таблицы:
| **Группа** | **Техника** | **Когда используется** |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Элементарные техники:
- сосредоточены на анализе входных / выходных параметров;
- можно комбинировать для лучшего покрытия;
- обычно не используют и не зависят от других методик;
| Equivalence Partitioning | Входные и выходные параметры имеют большое количество возможных значений |
| - | Boundary Value Analysis | Значения параметров имеют явные (например, четко определенные в документации) границы и диапазоны или неявные (например, известные технические ограничения) границы |
| | | |
| Комбинаторные стратегии:
- объединяют возможные значения нескольких параметров ввода / вывода;
- могут использовать элементарные приемы для уменьшения количества возможных значений;
| All Combinations | Количество возможных комбинаций входных значений достаточно мало, или каждая отдельная комбинация входных значений приводит к определенному выходному значению |
| - | Pairwise Testing | Количество входных комбинаций чрезвычайно велико и должно быть сокращено до приемлемого набора кейсов |
| - | Each Choice Testing | У вас есть функции, при которых скорее конкретное значение параметра вызывает ошибку, нежели комбинация значений |
| - | Base Choice Testing | Вы можете выделить набор значений параметров, который имеет наибольшую вероятность использования |
| Продвинутые техники:
- помогают проанализировать Систему с точки зрения бизнес-логики, иерархических отношений, сценариев и т. д.;
- анализ основан на данных, организованных в таблицы, диаграммы и шаблоны;
- может полагаться на элементарные и комбинаторные методы для разработки тестовых примеров;
| Decision Table Testing | Существует набор комбинаций параметров и их выходных данных, описываемых бизнес-логикой или другими правилами |
| - | Classification Tree Method | У вас есть иерархически структурированные данные, или данные могут быть представлены в виде иерархического дерева |
| - | State Transition Testing | В функциональности есть очевидные состояния, переходы которых регулируются правилами (например, потоки) |
| - | Cause-Effect Graphing | Причины (входы) и следствия (выходы) связаны большим количеством сложных логических зависимостей |
| - | Scenario Testing | В функционале есть четкие сценарии |
| Другие техники | Random Testing | Вам необходимо имитировать непредсказуемость реальных вводных данных, или функциональность имеет несистематические дефекты |
| - | Syntax Testing | Функциональность имеет сложный синтаксический формат для входных данных (например, коды, сложные имена электронной почты и т. д.) |
**Эквивалентное разделение (Equivalence Partitioning (ISTQB/Myers 1979) / Equivalence Class Testing (Lee Copeland))**
Класс эквивалентности представляет собой набор данных, которые либо одинаково обрабатываются модулем, либо их обработка выдает одинаковые результаты. При тестировании любое значение данных, входящее в класс эквивалентности, аналогично любому иному значению класса.
Эквивалентное разделение - это разделение всего набора данных ввода / вывода на такие разделы. Таким образом, вам не нужно выполнять тесты для каждого элемента подмножества, и достаточно одной проверки, чтобы охватить все подмножество. Хитрость заключается в том, чтобы увидеть и идентифицировать разделы, т.к. далеко не всегда они представляют собой числа.
Пример: Мы пишем модуль для системы отдела кадров, который определяет, в каком порядке нужно рассматривать заявления о приеме на работу в зависимости от возраста кандидата.
Правила нашей организации таковы:
* от 0 до 16 - не принимаются;
* от 16 до 18 - могут быть приняты только на неполный рабочий день;
* от 18 до 55 - могут быть приняты как сотрудники на полный рабочий день;
* от 55 до 99 - не принимаются;
Что в коде выглядит как:
* If (applicantAge >= 0 && applicantAge <=16)
* hireStatus="NO";
* If (applicantAge >= 16 && applicantAge <=18)
* hireStatus="PART";
* If (applicantAge >= 18 && applicantAge <=55)
* hireStatus="FULL";
* If (applicantAge >= 55 && applicantAge <=90)
* hireStatus="NO";
Из чего очевидно, что вместо 100 кейсов нам понадобится 4 по числу эквивалентных классов, все остальные кейсы внутри своих классов будут давать одинаковый результат тестов и являются избыточными.
Теперь мы готовы начать тестирование? Вероятно, нет. Что насчет таких входных данных как 969, -42, FRED или &$#! ? Должны ли мы создавать тестовые сценарии для некорректных входных данных? Для того, чтобы понять ответ, мы должны проверить подход, который пришел из объектно-ориентированного мира, названный "проектирование-по-контракту".
В подходе "проектирование-по-контракту" модули (в парадигме объектно-ориентированного программирования они называются "методами", но "модуль" является более общим термином) определены в терминах предусловий и постусловий. Постусловия определяют, что модуль обещает сделать (вычислить значение, открыть файл, напечатать отчет, обновить запись в базе данных, изменить состояние системы и т.д.). Предусловия описывают требования к модулю, при которых он переходит в состояние, описываемое постусловиями.
Например, если у нас есть модуль "openFile", что он обещает сделать? Открыть файл. Какие будут разумные предусловия для этого модуля?
* файл должен существовать,
* мы должны предоставить имя (или другую идентифицирующую информацию),
* файл должен быть "открываемым", т.е. он не может быть открытым в другом процессе,
* у нас должны быть права доступа к файлу и т.д.
Предусловия и постусловия основывают контракт между модулем и всеми, кто его вызывает. Тестирование-по-контракту основывается на философии проектирования-по-контракту. При использовании данного подхода мы создаем только те тест-кейсы, которые удовлетворяют нашим предусловиям. Например, мы не будем тестировать модуль "openFile", если файл не существует. Причина проста. Если файл не существует, то openFile не обещает работать. Если не существует требования работоспособности в определенных условиях, то нет необходимости проводить тестирование в этих условиях.
В этот момент тестировщики обычно возражают. Да, они согласны, что модуль не претендует на работу в этом случае, но что делать, если предусловия нарушаются в процессе разработки? Что делать системе? Должны ли мы получить сообщение об ошибке на экране или дымящуюся воронку на месте нашей компании? Другим подходом к проектированию является оборонительное проектирование. В этом случае модуль предназначен для приема любого входного значения. Если выполнены обычные предусловия, то модуль достигнет своих обычных постусловий. Если обычные предварительные условия не выполняются, то модуль сообщит вызывающему, возвратив код ошибки или бросив исключение (в зависимости от используемого языка программирования). На самом деле, это уведомление является еще одним из постусловий модуля.
На основе этого подхода мы могли бы определить оборонительное тестирование: подход, который анализирует как обычные, так и необычные предварительные условия.
Нужно ли нам делать проверку с такими входными значениями, как -42, FRED и &$#! @? Если мы используем проектирование-по-контракту и тестирование-по-контракту, то ответ "Нет". Если мы используем оборонительное проектирование и, поэтому, оборонительное тестирование, то ответ "Да". Спросите ваших проектировщиков, какой подход они используют. Если их ответом будет «контрактный» либо «оборонительный», то вы знаете, какой стиль тестирования использовать. Если они ответят "Хм?", то это значит, что они не думают о том, как взаимодействуют модули. Они не думают о предусловиях и постусловиях контрактов. Вам стоит ожидать, что интеграционное тестирование будет главным источником дефектов, будет более сложным и потребует больше времени, чем ожидалось.
Несмотря на то, что тестирование классов эквивалентности полезно, его величайшим вкладом является то, что оно приводит нас к тестированию граничных значений.
**Анализ граничных значений (BVA - Boundary Value Analysis (Myers 1979)/range checking)**
Тестирование классов эквивалентности - это самая основная методика тест-дизайна. Она помогает тестировщикам выбрать небольшое подмножество из всех возможных тестовых сценариев и при этом обеспечить приемлемое покрытие. У этой техники есть еще один плюс. Она приводит к идее о тестировании граничных значений - второй ключевой технике тест-дизайна.
Пример. Выше описывались правила, которые указывали, каким образом будет происходить обработка заявок на вакансии в зависимости от возраста соискателя.
Обратите внимание на проблемы на границах - это "края" каждого класса. Возраст "16" входит в два различных класса эквивалентности (как и "18", и "55"). Первое правило гласит не нанимать шестнадцатилетних. Второе правило гласит, что шестнадцатилетние могут быть наняты на неполный рабочий день Тестирование граничных значений фокусируется на границах именно потому, что там спрятано очень много дефектов. Опытные тестировщики сталкивались с этой ситуацией много раз. У неопытных тестировщиков может появиться интуитивное ощущение, что ошибки будут возникать чаще всего на границах. Эти дефекты могут быть в требованиях, или в коде, если программист ошибется с указанием границ в коде (включительно/не включительно, индекс +-1).
Попробуем исправить приведенный выше пример:
* от 0 до 15 - не принимаются;
* от 16 до 17 - могут быть приняты только на неполный рабочий день;
* от 18 до 54 - могут быть приняты как сотрудники на полный рабочий день;
* от 55 до 99 - не принимаются;
А что насчет возраста -3 и 101? Обратите внимание, что требования не указывают, как должны быть рассмотрены эти значения. Мы можем догадаться, но "угадывание требований" не является приемлемой практикой. Следующий код реализует исправленные правила:
* if (applicantAge >= 0 && applicantAge <= 15)
* hireStatus = "NO";
* if (applicantAge >= 16 && applicantAge <= 17)
* hireStatus = "PART";
* if (applicantAge >= 18 && applicantAge <= 54)
* hireStatus = "FULL";
* if (applicantAge >= 55 && applicantAge <= 99)
* hireStatus = "NO";
В этом примере интересными значениями на границах или вблизи них являются {-1, 0, 1}, {15, 16, 17}, {17, 18, 19}, {54, 55, 56} и {98, 99, 100}. Другие значения, например {-42, 1001, FRED, %$#@} могут быть включены в зависимости от предусловий документации модуля.
Для создания тест-кейсов для каждого граничного значения определите классы эквивалентности, выберите одну точку на границе, одну точку чуть ниже границы и одну точку чуть выше границы. Стоит отметить, что точка чуть выше границы может входить в другой класс эквивалентности. В таком случае не нужно дублировать тест. То же самое может быть верно по отношению точки чуть ниже границы.
Тестирование граничных значений является наиболее подходящим там, где входные данные являются непрерывным диапазоном значений.
**Тестирование таблиц решений (Decision Table testing)**
Этот простой, но эффективный метод заключается в документировании бизнес-логики в таблице как наборы правил, условий выполнения действий и самих действий. Тестирование таблиц принятия решений может быть использовано, когда система должна реализовывать сложные бизнес-правила, когда эти правила могут быть представлены в виде комбинации условий и когда эти условия имеют дискретные действия, связанные с ними.
Пример. Компания по автострахованию дает скидку водителям, которые состоят в браке и/или хорошо учатся.
| - | **Правило 1** | **Правило 2** | **Правило 3** | **Правило 4** |
| ---------------- | ------------- | ------------- | ------------- | ------------- |
| **Условия** | - | - | - | - |
| Состоит в браке? | Да | Да | Нет | Нет |
| Хороший студент? | Да | Нет | Да | Нет |
| - | - | - | - | - |
| **Действия** | - | - | - | - |
| Скидка ($) | 60 | 25 | 50 | 0 |
эта таблица содержит все комбинации условий. Задав два бинарных условия ("да" или "нет"), возможные комбинации будут: ("да", "да"), ("да", "нет"), ("нет", "да") и ("нет", "нет"). Каждое правило представляет собой одну из этих комбинаций. Нам, тестировщикам, нужно будет проверить, что определяются все комбинации условий. Пропущенное сочетание может привести к разработке такой системы, которая не сможет правильно обработать определенный набор исходных данных. Каждое правило является причиной "запуска" действия. Каждое правило может задать действие, уникальное для этого правила, или правила могут иметь общие действия. Для каждого правила с помощью таблицы решений можно указать более одного действия. Опять же, эти правила могут быть уникальными или быть общими. В такой ситуации выбрать тесты просто - каждое правило (вертикальная колонка) становится тест-кейсом. Условия указывают на входные значения, а действия - на ожидаемые результаты.
Если тестируемая система имеет сложные бизнес-правила, а у ваших бизнес-аналитиков или проектировщиков нет документации этих правил, то тестировщикам следует собрать эту информацию и представить ее в виде таблицы решений. Причина проста: представляя поведение системы в такой полной и компактной форме, тест-кейсы могут быть созданы непосредственно из таблицы решений. При тестировании для каждого правила создается как минимум один тест-кейс. Если состояния этого правила бинарные, то должно быть достаточно одного теста для каждого сочетания. С другой стороны, если состояние является диапазоном значений, то тестирование должно учитывать и нижнюю, и высшую границы диапазона. Таким образом мы объединяем идею тестирования граничных значений с тестированием таблиц решений.
Чтобы создать тестовую таблицу, просто измените заголовки строк и столбцов: правила станут тест-кейсами, условия входными значениями, а действия ожидаемыми результатами.
**Комбинаторные техники тест-дизайна (Combination Strategies)**
*Комбинаторное тестирование (combinatorial testing): Метод, позволяющий выделить подходящую подгруппу тестовых комбинаций с целью добиться предопределенного уровня покрытия при тестировании объекта с множественными параметрами в случаях, когда эти параметры сами по себе состоят из нескольких значений, что приводит к появлению большего числа комбинаций, чем можно успеть протестировать за отведенное время. См. также метод дерева классификации, попарное тестирование, n-мерное (переборное) тестирование, тестирование с использованием ортогонального массива. (ISTQB)*
Тестовые примеры выбираются на основе некоторого понятия покрытия, и цель стратегии комбинирования состоит в том, чтобы выбрать тестовые примеры из набора тестов таким образом, чтобы было достигнуто 100% покрытие.
* 1-wise coverage (each-used) - это самый простой критерий покрытия. Для 100% each-used покрытия требуется, чтобы каждое значение каждого параметра было включено хотя бы в один тестовый пример в наборе тестов.
* 2-wise (pair-wise) coverage требует, чтобы каждая возможная пара значений любых двух параметров была включена в некоторый тестовый пример. Обратите внимание, что один и тот же тестовый пример часто охватывает более одной уникальной пары значений.
* Естественным продолжением 2-wise coverage является t-wise coverage, которое требует включения всех возможных комбинаций интересных значений параметров t в какой-либо тестовый пример в наборе тестов.
* Самый тщательный критерий покрытия, N-wise coverage, требует набора тестов, который содержит все возможные комбинации значений параметров в input parameter model (IPM).
**Все комбинации** (All combinations): как видно из названия, этот алгоритм подразумевает генерацию всех возможных комбинаций. Это означает исчерпывающее тестирование и имеет смысл только при разумном количестве комбинаций. Например, 3 переменные с 3 значениями для каждой дают нам матрицу параметров 3х3 с 27 возможными комбинациями.
**Тестирование каждого выбора** (EC - Each choice testing): эта стратегия требует, чтобы каждое значение каждого параметра было включено по крайней мере в один тестовый пример (Ammann & Offutt, 1994). Это также определение 1-wise coverage.
**Тестирование базового выбора** (BC - Base choice testing): алгоритм стратегии комбинирования базового выбора начинается с определения одного базового тестового примера. Базовый тестовый пример может быть определен по любому критерию, включая простейший, наименьший или первый. Критерий, предложенный Амманном и Оффуттом (Ammann & Offutt, 1994), - это «наиболее вероятное значение» с точки зрения конечного пользователя. Это значение может быть определено тестировщиком или основано на рабочем профиле, если таковой существует. Из базового тестового примера создаются новые тестовые примеры, изменяя интересующие значения одного параметра за раз, сохраняя значения других параметров фиксированными в базовом тестовом примере. Базовый выбор включает каждое значение каждого параметра по крайней мере в одном тестовом примере, поэтому он удовлетворяет 1-wise coverage.
**Попарное тестирование** (Pairwise testing)
Pairwise testing - техника тест-дизайна, а именно метод обнаружения дефектов с использованием комбинационного метода из двух тестовых случаев. Он основан на наблюдениях о том, что большинство дефектов вызвано взаимодействием не более двух факторов (дефекты, которые возникают при взаимодействии трех и более факторов, как правило менее критичны). Следовательно, выбирается пара двух тестовых параметров, и все возможные пары этих двух параметров отправляются в качестве входных параметров для тестирования. Pairwise testing сокращает общее количество тест-кейсов, тем самым уменьшая время и расходы, затраченные на тестирование. Захватывающей надеждой попарного тестирования является то, что путем создания и запуска 1-20% тестов вы найдете 70-85% от общего объема дефектов.
Пример: По ТЗ сайт должен работать в 8 браузерах, используя различные плагины, запускаться на различных клиентских операционных системах, получать страницы от разных веб-серверов, работать с различными серверными, операционными системами. Итого:
* 8 браузеров;
* 3 плагина;
* 6 клиентских операционных систем;
* 3 сервера;
* 3 серверных операционных системы;
\= 1296 комбинаций. Количество комбинаций настолько велико, что, скорее всего, у нас не хватит ресурсов, чтобы спроектировать и пройти тест-кейсы. Не следует пытаться проверить все комбинации значений для всех переменных, а нужно проверять комбинации пар значений переменных.
Использование всех пар для создания тест-кейсов основывается на двух техниках:
* ортогональные массивы (OA - Orthogonal Array): это двумерный массив символов. На примере выше мы составляем таблицу, где столбцы представляют собой переменные (браузер, плагин, клиентская операционная система, веб-сервер и серверная операционная система, а строки - значения каждой переменной (Chrome/Opera, Windows 8/10/11 и т.п.). После чего нужно определить ортогональный массив, у которого будет столбец для каждой переменной (каждый столбец ортогонального массива имеет столько же вариантов значений, сколько имеет ваша переменная). Используя ортогональный массив для примера выше, все пары всех значений всех переменных могут быть покрыты всего лишь 64-мя тестами.
* алгоритм Allpairs: генерирует пары непосредственно, не прибегая к таким к ортогональным массивам. "Несбалансированный" характер алгоритма выбора всех пар требует только 48 тестов для примера. Следует отметить, что комбинации, выбранные методом ортогонального массива, могут быть не такими же, как те, которые выбраны Allpairs. Но это не важно. Важно лишь то, чтобы были выбраны все парные комбинации параметров. Это будут комбинации, которые мы хотим проверить.
Подробнее с разбором примера см. у Копленда в главе 6.
На практике же вручную эти массивы никто не формирует, всю механику реализуют автоматизированные инструменты, самый популярный из них PICT. Тестировщику остается лишь подготовить и скормить данные.
**Classification tree method**
*Метод дерева классификации (classification tree method): Разработка тестов методом черного ящика, в которой тестовые сценарии, описанные средствами дерева классификации, разрабатываются для проверки комбинаций выборок входных и/или выходных подмножеств. (Grochtmann) См. также комбинаторное тестирование.*
Дерево классификации (Classification tree): структура, показывающее иерархически упорядоченные классы эквивалентности, которое используется для разработки тестовых примеров в методе дерева классификации (Classification tree method). Не путать с [Decision tree](https://en.wikipedia.org/wiki/Decision_tree).
Метод дерева классификации: вид комбинаторной техники, в которой тестовые примеры, описанные с помощью дерева классификации, предназначены для выполнения комбинаций представителей входных и / или выходных доменов.

Чтобы рассчитать количество тестовых примеров, нам необходимо проанализировать требования, определить соответствующие тестовые функции (классификации) и их соответствующие значения (классы).
Обычно для создания Classification tree используется инструмент Classification Tree Editor. Если же взять лист бумаги и ручку, то у нас есть тестовый объект (целое приложение, определенная функция, абстрактная идея и т. д.) вверху как корень. Мы рисуем ответвления от корня как классификации (проверяем соответствующие аспекты, которые мы определили). Затем, используя классы эквивалентности и анализ граничных значений, мы определяем наши листья как классы из диапазона всех возможных значений для конкретной классификации. И если некоторые из классов могут быть классифицированы далее, мы рисуем под-ветку / классификацию с собственными листьями / классами. Когда наше дерево завершено, мы делаем проекции листьев на горизонтальной линии (Test case), используя одну из комбинаторных стратегий (all combinations, each choice и т. д.), и создаем все необходимые комбинации.
Максимальное количество тестовых примеров - это декартово произведение всех классов всех классификаций в дереве, быстро приводящее к большим числам для реалистичных тестовых задач. Минимальное количество тестовых примеров - это количество классов в классификации с наиболее содержащимися классами. На втором этапе тестовые примеры составляются путем выбора ровно одного класса из каждой классификации дерева классификации.
**Тестирование переходов между состояниями (State Transition testing)**
*Таблица состояний (state table): Таблица, показывающая конечные переходы для каждого состояния вследствие каждого возможного события, как для корректных, так и для некорректных переходов. (ISTQB)*
Тестирование переходов между состояниями определяется как метод тестирования ПО, при котором изменения входных условий вызывают изменения состояния в тестируемом приложении (AUT). В этом методе тестировщик предоставляет как положительные, так и негативные входные значения теста и записывает поведение системы. Это модель, на которой основаны система и тесты. Любая система, в которой вы получаете разные выходные данные для одного и того же ввода, в зависимости от того, что произошло раньше, является системой конечных состояний. Техника тестирования переходов между состояниями полезна, когда вам нужно протестировать различные системные переходы. Этот подход лучше всего подходит там, где есть возможность рассматривать всю систему как конечный автомат. Для наглядности возьмем классический пример покупки авиабилетов:
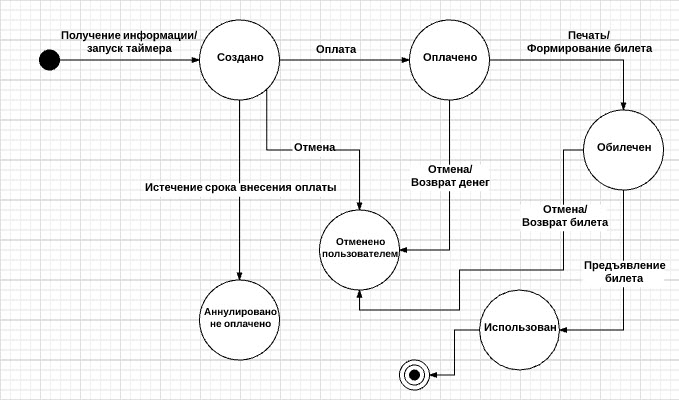
* Состояние (state, представленное в виде круга на диаграмме) - это состояние приложения, в котором оно ожидает одно или более событий. Состояние помнит входные данные, полученные до этого, и показывает, как приложение будет реагировать на полученные события. События могут вызывать смену состояния и/или инициировать действия;
* Переход (transition, представлено в виде стрелки на диаграмме) - это преобразование одного состояния в другое, происходящее по событию;
* Событие (event, представленное ярлыком над стрелкой) - это что-то, что заставляет приложение поменять свое состояние. События могут поступать извне приложения, через интерфейс самого приложения. Само приложение также может генерировать события (например, событие «истек таймер»). Когда происходит событие, приложение может поменять (или не поменять) состояние и выполнить (или не выполнить) действие. События могут иметь параметры (например, событие «Оплата» может иметь параметры «Наличные деньги», «Чек», «Приходная карта» или «Кредитная карта»);
* Действие (action, представлено после «/» в ярлыке над переходом) инициируется сменой состояния («напечатать билет», «показать на экране» и др.). Обычно действия создают что-то, что является выходными/возвращаемыми данными системы. Действия возникают при переходах, сами по себе состояния пассивны;
* Точка входа обозначается черным кружком;
* Точка выхода показывается на диаграмме в виде мишени;
Все начинается с точки входа. Мы (клиенты) предоставляем авиакомпании информацию для бронирования. Служащий авиакомпании является интерфейсом между нами и системой бронирования авиабилетов. Он использует предоставленную нами информацию для создания бронирования. После этого наше бронирование находится в состоянии «Создано». После создания бронирования система также запускает таймер. Если время таймера истекает, а забронированный билет еще не оплачен, то система автоматически снимает бронь.
Каждое действие, выполненное над билетом, и соответствующее состояние (отмена бронирования пользователем, оплата билета, получение билета на руки, и т. д.) отображаются в блок-схеме.
На основании полученной схемы составляется набор тестов.
Определим четыре разных уровня покрытия:
1. Набор тестов, в котором все состояния будут посещены как минимум один раз. Этому требованию удовлетворяет набор из трех тестов, показанный ниже. Обычно это низкий уровень тестового покрытия.
2. Набор тестов, в котором все события выполнятся как минимум один раз. Следует отметить, что тест-кейсы, которые покрывают каждое событие, могут быть точно теми же, которые покрывают каждое состояние. Опять же, это низкий уровень покрытия.
3. Набор тестов, в котором все пути будут пройдены как минимум один раз. Несмотря на то, что этот уровень является наиболее предпочтительным из-за его уровня покрытия, это может быть неосуществимо. Если диаграмма состояний и переходов содержит петли, то количество возможных путей может быть бесконечным.
4. Набор тестов, в котором все переходы будут осуществлены как минимум один раз. Этот уровень тестирования обеспечивает хороший уровень покрытия без порождения большого количества тестов. Этот уровень, как правило, один из рекомендованных.
Диаграмма состояний и переходов - не единственный способ документирования поведения системы. Диаграммы, возможно, легче в понимании, но таблицы состояний и переходов могут быть проще в использовании на постоянной и временной основе. Таблицы состояний и переходов состоят из четырех столбцов - "Текущее состояние", "Событие", "Действие" и "Следующее состояние". Преимущество таблицы состояний и переходов в том, что в ней перечисляются все возможные комбинации состояний и переходов, а не только допустимые. При крайне необходимом тестировании систем с высокой степенью риска, например авиационной радиоэлектротехники или медицинских устройств, может потребоваться тестирование каждой пары состояние-переход, включая те, которые не являются допустимыми. Кроме того, создание таблицы состояний и переходов часто извлекает комбинации, которые не были определены, задокументированы или рассмотрены в требованиях. Очень полезно обнаружить эти дефекты до начала кодирования.
Использование таблицы состояний и переходов может помочь обнаружить дефекты в реализации, которые позволяют недопустимые пути из одного состояния в другое. Недостатком таких таблиц является то, что, когда количество состояний и событий возрастает, они очень быстро становятся огромными. Кроме того, в таблицах, как правило, большинство клеток пустые.
Подробнее с разбором примера см. у Копленда в главе 7.
**Domain testing**
*Анализ доменов (domain analysis): Методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. Методика базируется и обобщает методы эквивалентного разбиения и анализа граничных значений/ (ISTQB)*
В главах по тестированию классов эквивалентности и граничных значений мы рассмотрели тестирование одиночных переменных, которые требовали оценки в указанных диапазонах. В этой главе мы рассмотрим тестирование нескольких переменных одновременно. Существуют две причины, по которым стоит обратить на это внимание:
* у нас редко будет достаточно времени на создание тест-кейсов для каждой переменной в нашей системе. Их просто слишком много;
* часто переменные взаимодействуют. Значение одной переменной ограничивает допустимые значения другой. В этом случае, если проверять переменные поодиночке, можно не обнаружить некоторые дефекты;
Domain-тестирование - это техника, которая может применяться для определения эффективных и действенных тест-кейсов, когда несколько переменных (например, поля ввода) должны проверяться вместе - либо для эффективности, либо по причине их логического взаимодействия. Она использует и обобщает тестирование классов эквивалентности и граничных значений в n одномерных измерениях. Подобно этим техникам, мы ищем случаи, где граница была неверно определена или реализована. Несмотря на то, что эта техника лучше всего подходит для числовых значений, она может быть обобщена и на другие типы - boolean, string, enumeration и т.д.
В двухмерном измерении (с двумя взаимодействующими параметрами) могут возникнуть следующие дефекты:
* сдвиг границы - граница, перемещённая вертикально или горизонтально;
* направление границы - граница, повёрнутая под неправильным углом;
* пропущенная граница;
* лишняя граница

Подробнее с разбором примера см. у Копленда в главе 8.
**Use case-based Testing**
*Сценарий использования системы (use case): Последовательность операций во взаимодействии актера и компонента или системы со значимым результатом, при которой актером может быть как пользователь, так и все, что может обмениваться информацией с системой. (ISTQB)*
До сих пор мы исследовали техники разработки тестовых сценариев для частей системы - входные переменные с их диапазонами и границами, бизнес-правила, представленные в виде таблиц решений, а также поведения системы, представленные с помощью диаграмм состояний и переходов. Теперь пришло время рассмотреть тестовые сценарии, которые используют системные функции с начала и до конца путем тестирования каждой из их индивидуальных операций.
Сегодня самым популярным подходом определения выполняемых системой операций является [диаграмма вариантов использования](https://habr.com/ru/post/566218/) (диаграмма прецедентов, Use case diagram). Как и таблицы решений и диаграммы состояний и переходов, диаграммы вариантов использования обычно создаются разработчиками для разработчиков. Но, как и другие техники, диаграммы вариантов использования содержат много полезной информации и для тестировщиков. Варианты использования были созданы Иваром Якобсоном и объяснены в его книге "Объектно-ориентированная разработка программ: подход, основанный на вариантах использования". Якобсон определил
Вариант использования (Use Case) - это сценарий, который описывает использование системы действующим лицом для достижения определенной цели (Ивар Якобсон - "Объектно-ориентированная разработка программ: подход, основанный на вариантах использования").
* Действующее лицо (или актер) - это пользователь, играющий роль с уважением к системе, старающегося использовать систему для достижения чего-то важного внутри конкретного контекста. Действующими лицами в основном являются люди, хотя действующими лицами также могут выступать другие системы;
* "Сценарий" - это последовательность шагов, которые описывают взаимодействия между актером и системой. Заметьте, что варианты использования определены с точки зрения пользователя, а не системы. Заметьте также, что операции, выполняемые внутри системы, хоть и важны, но не являются частью определения вариантов использования. Набор вариантов использования составляет функциональные требования системы.
Прежде чем использовать сценарии для создания Test case, их необходимо подробно описать с помощью шаблона. Шаблоны могут варьироваться от проекта к проекту. Но среди таких обычных полей, как имя, цель, предварительные условия, актер (ы) и т. д., всегда есть основной успешный сценарий и так называемые расширения (плюс иногда подвариации). Расширения - это условия, которые влияют на основной сценарий успеха. А подвариации - это условия, которые не влияют на основной flow, но все же должны быть рассмотрены. После того, как шаблон заполнен данными, мы создаем конкретные Test case, используя методы эквивалентного разделения и граничных значений. Для минимального охвата нам нужен как минимум один тестовый сценарий для основного сценария успеха и как минимум один Test case для каждого расширения. Опять же, этот метод соответствует общей формуле «получите условия, которые меняют наш результат, и проверьте комбинации». Но способ получить это - проанализировать поведение Системы с помощью сценариев.
Польза вариантов использования в том, что они:
* позволяют выявить функциональные требования системы с точки зрения пользователя несмотря на техническую перспективу и независимо от того, какая парадигма разработки использовалась;
* могут быть использованы для активного вовлечения пользователей в процесс сбора требований и определений;
* предоставляют базис для идентификации ключевых компонентов системы, структур, баз данных и связей;
* служат основанием для разработки тест-кейсов системы на приемочном уровне.
Подробнее с разбором примера см. у Копленда в главе 8.
Как создать хорошие сценарии (Сэм Канер):
1. Напишите истории жизни для объектов в системе.
2. Перечислите возможных пользователей, проанализируйте их интересы и цели.
3. Подумайте об отрицательных пользователях: как они хотят злоупотреблять вашей системой?
4. Перечислите «системные события». Как система справляется с ними?
5. Перечислите «особые события». Какие приспособления система делает для них?
6. Перечислите преимущества и создайте сквозные задачи, чтобы проверить их.
7. Интервью пользователей об известных проблемах и сбоях старой системы.
8. Работайте вместе с пользователями, чтобы увидеть, как они работают и что они делают.
9. Читайте о том, что должны делать подобные системы.
10. Изучите жалобы на предшественника этой системы или ее конкурентов.
11. Создать фиктивный бизнес. Относитесь к нему как к реальному и обрабатывайте его данные.
12. Попробуйте преобразовать реальные данные из конкурирующего или предшествующего приложения.
**Cause/Effect, Cause-Effect (CE)**
*Таблица причинно-следственных решений (cause-effect decision table): См. таблица решений.*
*Таблица решений (decision table): Таблица, отражающая комбинации входных данных и/или причин с соответствующими выходными данными и/или действиям (следствиям), которая может быть использована для проектирования тестовых сценариев. (ISTQB)*
Тестовые примеры должны быть разработаны так, чтобы проявлять принципы, которые характеризуют взаимосвязь между входными и выходными данными компонента, где каждый принцип соответствует единственной возможной комбинации входных данных компонента, которые были выражены как логические значения. Для каждого тестового примера следует уточнить:
* Логическое состояние для каждого эффекта;
* Логическое состояние (истина или ложь) по любой причине;
Граф причинно-следственных связей (Cause-Effect Graph) использует такую модель логических взаимосвязей между причинами и следствиями для компонента. Каждая причина выражается как условие, которое может быть истинным, ложным на входе или комбинацией входных данных компонента. Каждый эффект выражается в виде логического выражения, представляющего результаты или комбинацию результатов для произошедшего компонента (?Every effect is expressed as a Boolean expression representing results, or a combination of results, for the component having occurred). Модель обычно представлена как логический граф, связывающий производные логические выражения ввода и вывода с использованием логических операторов:
* И (AND);
* ИЛИ (OR);
* Истина, если не все входные данные верны («не оба») ([NAND](https://en.wikipedia.org/wiki/NAND_gate));
* Истина, когда ни один из входов не является истиной ("ни один") ([NOR](https://en.wikipedia.org/wiki/NOR_gate));
* НЕ (NOT).
Cause-Effect Graph также известен как диаграмма Исикавы, поскольку он был изобретен Каору Исикава, или как диаграмма рыбьей кости из-за того, как он выглядит.
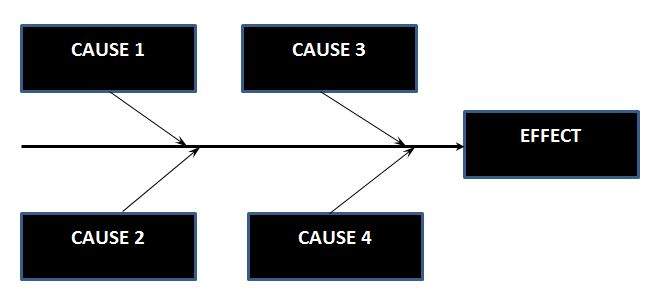
Граф причинно-следственных связей похож на Decision Table и также использует идею объединения условий. И иногда они описываются как один метод. Но если между условиями существует много логических зависимостей, может быть проще их визуализировать на cause-effect graph.
**Syntax testing**
*Синтаксическое тестирование (syntax testing): Разработка тестов методом черного ящика, в которой тестовые сценарии строятся на основе области определения входящих и/или выходных значений. (ISTQB)*
Синтаксическое тестирование используется для проверки формата и правильности входных данных в случаях символьных текстовых полей, проверки соответствия формату файла, схеме базы данных, протоколу и т.д., при этом данные могут быть формально описаны в технических или установленных и определенных обозначениях, таких как BNF ([Форма Бэкуса - Наура](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D0%B0_%D0%91%D1%8D%D0%BA%D1%83%D1%81%D0%B0_%E2%80%94_%D0%9D%D0%B0%D1%83%D1%80%D0%B0)).

Как правило, синтаксические тесты автоматизированы, так как они предполагают создание большого количества кейсов. Синтаксис тестируется с использованием двух условий:
* Валидные: Проверка нормального состояния с использованием покрывающего набора путей синтаксического графа для минимально необходимых требований (?Testing the normal condition using the covering set of paths of the syntax graph, for the minimum necessary requirements). Иными словами находим возможные варианты значений, допускаемые отдельными элементами определения BNF, а затем разрабатываем кейсы, чтобы просто охватить эти варианты;
* Невалидные: Проверка мусорных условий (garbage condition)\* с использованием недопустимого набора входных данных.
Примечание \*: Мусорные условия - это метод проверки устойчивости системы к неверным или грязным данным. Условие выполняется путем предоставления в систему грязных данных (недопустимых данных), которые не поддерживаются указанным форматом и грамматикой синтаксиса. Для создания таких данных мы определяем и применяем возможные мутации (например, отсутствующий элемент, нежелательный дополнительный элемент, недопустимое значение для элемента и т. д.) к отдельным элементам определения BNF. Затем мы разрабатываем наши кейсы, применяя мутации, которые могут давать отличительные результаты (случаи, которые приводят к действительным комбинациям, исключаются).
**Check List Based Testing**
Тестирование на основе контрольного списка (чеклиста) выполняется с использованием предварительно подготовленного опытными тестировщиками чеклиста, который продолжает обновляться с учетом любых новых дефектов, обнаруженных при выполнении контрольных примеров контрольного списка. При любых изменениях в продукте прогоняется быстрый чеклист, чтобы убедиться, что из-за изменений не возникло новых дефектов. Этот контрольный список не имеет отношения к пользовательским историям.
**User Journey Test**
User Journey test, как следует из названия, охватывает полное путешествие пользователя по системе. Он охватывает сквозные тесты, из-за которых процент покрытия тестами больше по сравнению с другими методами. Этот метод помогает уменьшить количество тестовых примеров, поскольку тестовые примеры являются исчерпывающими и охватывают большую часть функциональности в одном сценарии. Сценарии написаны для самого сложного путешествия. Тесты взаимодействия с пользователем не связаны с пользовательскими историями (user stories).
**User Story Testing (Agile)**
Пользовательская история - это краткое и простое описание требований клиентов или конечного пользователя. Пользовательские истории написаны владельцем продукта (Product owner), поскольку именно он получает от клиента информацию о продукте, который будет создан. Если пользовательская история большая, она разбивается на несколько более мелких историй. Истории пользователей записываются на учетных карточках и вывешиваются на стене для обсуждения. Обсуждая важные аспекты функции, выберите те, которые в дальнейшем используются в пользовательской истории. Приемочные испытания - это заключительный этап, на котором продукт принимает заказчик после того, как он соответствует всем критериям выхода. Критерии приемлемости определяются владельцем продукта, заказчик на поставку также может привлекать разработчиков, определяя то же самое.
**Exhaustive testing**
*Исчерпывающее тестирование (exhaustive testing): Методика тестирования, в которой набор тестов включает в себя все комбинации входных данных и предусловий. (ISTQB)*
Исчерпывающее тестирование (Exhaustive testing - ET) - это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода почти всегда не представляется возможным, из-за огромного количества входных значений.
Источники:
* Ли Копланд - “A Practitioner's Guide to Software Test Design”, Главы 3-9
* [Test Design Techniques overview](https://sysgears.com/articles/test-design-techniques-overview/)
* [An Evaluation and comparison of practical results of Combination Strategies for Test Case Selection](https://cs.gmu.edu/~offutt/rsrch/papers/evalcombstrat.pdf)
* [Handling constraints in the input space when using combination strategies for software testing](https://www.researchgate.net/publication/228674683_Handling_constraints_in_the_input_space_when_using_combination_strategies_for_software_testing)
* [State Transition testing](https://quality-lab.ru/blog/roles-and-responsibilities-of-test-designer/)
* [Classification Tree Method](https://en.wikipedia.org/wiki/Classification_Tree_Method)
* [Black Box Test Techniques. Cause-Effect Graphing](https://blog.qatestlab.com/2011/09/13/black-box-test-techniques-cause-effect-graphing/)
* [Syntax Testing](https://www.professionalqa.com/syntax-testing)
* [Popular Software Testing Techniques With Examples](https://www.softwaretestinghelp.com/software-testing-techniques-2)
Доп. материал:
* [Плейлист "Тест-дизайн"](https://www.youtube.com/playlist?list=PLbHzpTP8TBBGBWhfLijaI6Nb8-0dFw4Qg)
* [Тестирование областей определения или классы эквивалентности + анализ граничных значений + pairwise](https://habr.com/ru/amp/post/270909/)
* [Классы эквивалентности](https://www.youtube.com/watch?v=MacODm0nh9o)
* [Классы эквивалентности для населенных пунктов в адресах](https://okiseleva.blogspot.com/2019/10/blog-post_30.html)
* [Классы эквивалентности для имен](https://okiseleva.blogspot.com/2019/10/blog-post_20.html)
* [Классы эквивалентности для строки, которая обозначает число](https://www.software-testing.ru/library/testing/functional-testing/1238-number-string-subdomains)
* [Классы эквивалентности для строки, которая обозначает дату](http://okiseleva.blogspot.com/2018/04/blog-post_14.html)
* [Класс эквивалентности «Ноль-не ноль»](http://okiseleva.blogspot.com/2016/12/blog-post_15.html)
* [James Bach, Patrick J. Schroeder - “Pairwise Testing: A Best Practice That Isn’t”](http://www.testingeducation.org/wtst5/PairwisePNSQC2004.pdf)
* [Paul Ammann & Jeff Offutt - “Input Space Partition Testing”](http://cc.ee.ntu.edu.tw/~farn/courses/ST/slides/Ch4-ISP.pdf)
* [Jeff Offutt & Sten F. Andler - “Combination Testing Strategies”](https://cs.gmu.edu/~offutt/rsrch/papers/combstrat-survey.pdf)
* [Тестировщик с нуля / Урок 9. Техники тест-дизайна. Классы эквивалентности и граничные значения](https://www.youtube.com/watch?v=HJPF5qJx7jg)
* [Попарное тестирование / Pairwise testing / PICT для тестировщика](https://www.youtube.com/watch?v=-Lu27061BiY)
* [Комбинаторное тестирование: примеры с PICT](https://habr.com/ru/company/infopulse/blog/261381/)
* [Pairwise Testing - Обзор веб инструментов для попарного тестирования](https://www.youtube.com/watch?v=Lzr9gb8TyqE)
* [Reducing Environment Combinations with Microsoft PICT](https://pragmatic-qa.com/pairwise-testing-with-pict/)
* [Pairwise Testing](https://www.microsoft.com/en-us/research/wp-content/uploads/2017/01/160.pdf)
* [Test Run - Pairwise Testing with QICT](https://docs.microsoft.com/en-us/archive/msdn-magazine/2009/december/test-run-pairwise-testing-with-qict)
* [Попарное тестирование: суть техники, инструменты и примеры](https://habr.com/ru/company/otus/blog/592575/)
* [Cem Kaner - ”Introduction to Domain Testing”](https://bbst.courses/wp-content/uploads/2018/01/Kaner-Intro-to-Domain-Testing-2018.pdf)
* [Шаблон Requirement Traceability Matrix](https://biconsult.ru/node/561)
* [Cause-Effect Graph example](https://www.softwaretestingclass.com/what-is-cause-and-effect-graph-testing-technique/)
* [https://app.diagrams.net/](https://app.diagrams.net)
* [Decision Table - что это и как применять](https://habr.com/ru/post/546432/)
* [Таблица решений для тестирования фильтрации с зависимыми фильтрами](https://habr.com/ru/post/664952/)
* [Тестирование состояний и переходов / Таблица принятия решений](https://www.youtube.com/watch?v=e84cyz2HC24)
* [State & Transition Diagram - что это и как применять](https://habr.com/ru/post/548192/)
* [Тестирование состояний и переходов / Таблица принятия решений](https://www.youtube.com/watch?v=e84cyz2HC24)
* [State Transition на примере тортика!](https://okiseleva.blogspot.com/2018/10/state-transition.html)
* [Примеры диаграммы State Transition Testing](https://okiseleva.blogspot.com/2018/07/state-transition-testing.html)
* [Как составлять вариант использования](https://okiseleva.blogspot.com/2015/11/blog-post_86.html)
* [Что такое use case? Теория и примеры](https://testengineer.ru/chto-takoe-use-case/)
* [Тест- дизайн. Техники тест- дизайна. Часть #1](https://youtu.be/tLS9Ar2Hypk)